


How to Protect Patient Privacy
Validating AnonCAT a transformer based approach for redaction of text from electronic health records across three NHS Trusts.

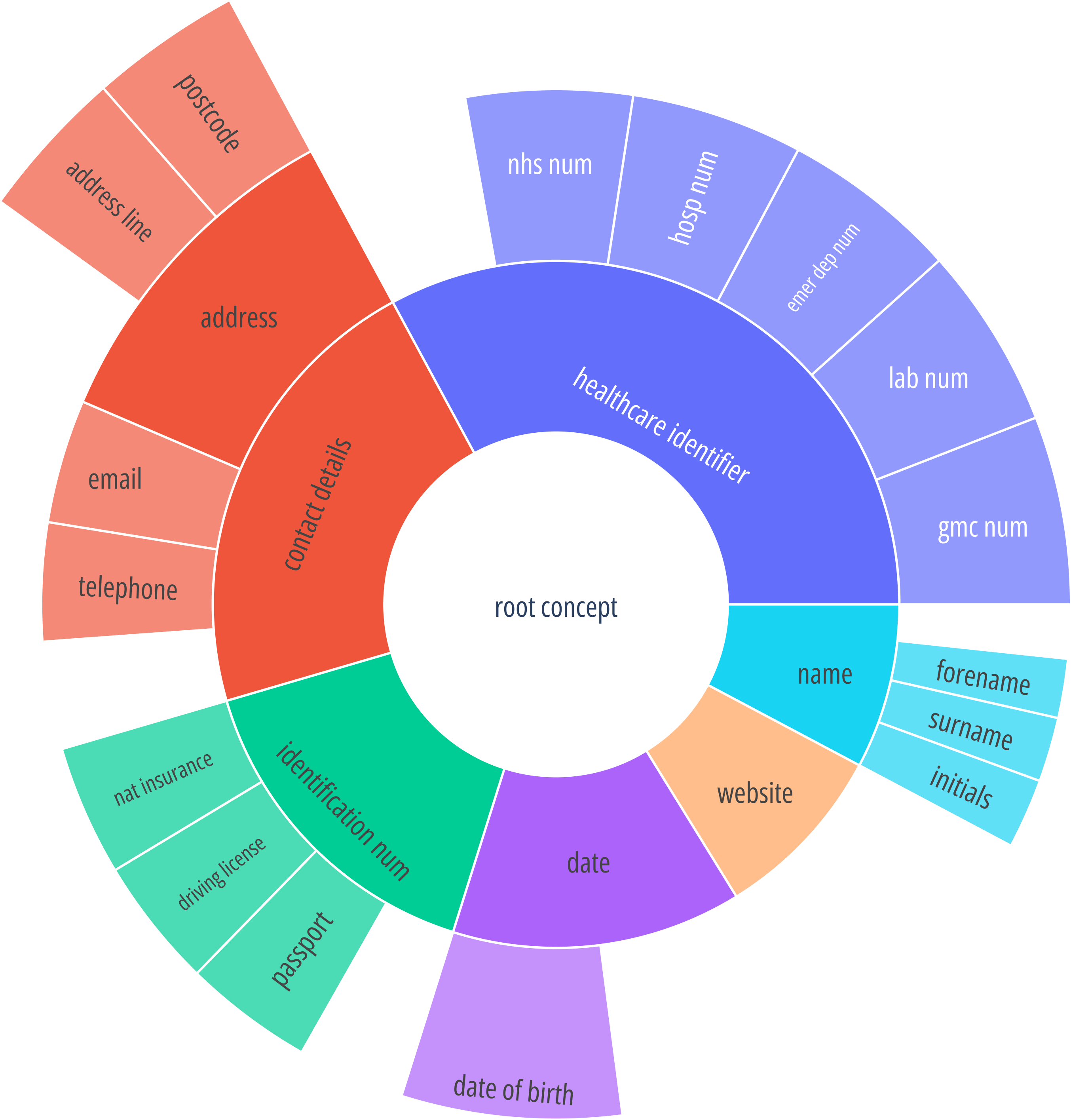
Before AI researchers1 can get access to patient data, it has to be de-identified, in other words, Personal Health Information - PHI2 (Figure 1) has to be removed or masked. The primary reason for doing this is to protect patient privacy, but it can be split into two parts:
First, researchers should not be able to see patient PHI.
Second, AI models should not learn from identifiable data and remember patient PHI (models like Large Language Models (LLM) remember a big portion of training data, as exemplified in Figure 2. The model remembered the name Bill Gates, and while in this case, it is not dangerous, it could be much more problematic if the model was trained on hospital data and remembered the whole patient records associated with Bill Gates).

But why do AI researchers even need access to hospital data? There are many different reasons but they all come down to one - if we want to make AI models that can help patients and doctors, we need to train and test them on real-world data and use cases (see Using AI to diagnose patients).
The rest of this post will present highlights from a recent paper I’ve done: AnonCAT - Deploying transformers for redaction of text from electronic health records in real-world healthcare (preprint, the paper will be presented at IEEE ICHI in June 2023).
Introduction
Healthcare systems contain vast amounts of unstructured health data stored in text form, more than 80% of patient data is free text3. As an example, King’s College Hospital in London has more than 20 million free text documents associated with ~1.5M patients4. In other words, free text is one of the richest sources of patient information we have. Compared to structured data, free text is significantly harder to de-identify, patient information can be embedded into the text in every imaginable way (Example of a clinical note in Figure 3 - left).

When de-identifying free text documents we have two main tasks: 1) Find all PHI data, do not miss anything; 2) Find only PHI data, do not remove anything else. We use two different metrics to measure how good a model is at each one of the two tasks. Precision is used for task 2, and Recall for task 1. Formally Precision and Recall are defined as:
Here, in case of de-identification:
TP - True Positive - How many pieces of PHI did the model correctly detect.
FN - False Negative - How many pieces of PHI did the model miss.
FP - False Positive - How many random pieces of text did the model detect as PHI even though they are not PHI.
Precision and Recall go hand in hand. Imagine a scenario where the model simply says all possible text in a document is PHI, by default this would mean that Recall is 1 because the model did find all PHI data. But, in this case, the Precision is extremely low (close to 0) because the model mistakenly removed a large amount of data that is not PHI, effectively making the dataset useless. On the other side, if the model detects only one piece of PHI data and misses everything else, the Precision will be 1, while Recall will be very low (close to 0).
A good model will have both Recall and Precision close to or equal to 1.
Methods for de-identification
In general, we can split the methods into more traditional ones (e.g. rule-based) and deep learning approaches (e.g. Transformers like BERT). A good method should solve the following three challenges:
Precision and Recall - this is the primary challenge. Both metrics have to be extremely high, our aim should be above 0.95.
Generalisability - there is a large number of differences in the patient record structure and language used across various departments, hospitals and countries. A good method has to be able to handle the variation.
Data drift - over time data changes, new formats are introduced, the way of writing changes, new diseases appear, etc. A good method should be easily adaptable to such changes.
Traditional methods
These methods usually consist of making a large number of rules for finding PHI data. For example, a rule can be something like:
Everything that follows the words Dr. Mr. or Ms. is a name and should be removed. Writing these rules is a painstaking process and can take a lot of time (months), especially for patient data as PHI can appear in every shape and form. But even though these methods can solve the three challenges mentioned above, the cost is often too high (too much time required, can only be done by experts familiar with all existing rules).
Deep learning approaches
In this case, we train a model to do the de-identification. Such models require training data, in other words, we have to take a set of patient documents and manually annotate what part of them is PHI data. In general, this approach is easier but can still take quite a bit of time (weeks) because of the manual annotations.
AnonCAT
The model we’ve developed is a deep-learning approach based on RoBERTa-large. We show that fine-tuning coupled with an iterative annotation process can solve the three challenges while still being easy to maintain and requiring only a small number of manual annotations.
Fine-tuning
We start by training a base (foundational) model for de-identification on a large manually annotated diverse dataset. After that, when transferring the model to a new hospital we manually annotate a small number of documents in the new hospital and fine-tune the base model. As we will see below, this ensures a high performance on new datasets (hospitals) and can be done quickly.
Iterative annotation process
Annotating documents can be a difficult process, in the case of de-identification (because of the requirement for very high precision and recall) the biggest challenge is that the annotations have to be perfect, otherwise, the model will not be able to learn properly. When annotating long patient documents that are full of PHI, it is very easy to miss initials, names, or pieces of an address. To prevent this we propose a novel annotation process where the model is used to validate the manual annotations, the steps are as follows (Figure 4):
Take a random sample of documents from an EHR.
Clinicians/Annotators manually annotate the sampled dataset.
Split the annotated dataset into 5 folds and train 5 different models, each one using a different fold for the test set.
Find all false positive (FP) and false negative (FN) examples from the 5 test sets.
Manually check each FP and FN, if the FP/FN is a mistake from the annotator, we fix the annotation (this creates a new dataset) and return to step 3. If all the FNs and FPs are mistakes by the model, we proceed to the next step.
Once all FPs/FNs are validated and manual annotations are fixed, the process is completed.

Experimental Setup
AnonCAT was tested on three different datasets: 1) A random sample of 2648 documents from the EHR at King's College Hospital NHS Foundation Trust (KCH) 2) A random sample of 328 documents from an existing recruited patient brain tumour cohort at Guy's and St Thomas' NHS Foundation Trust (GSTT); and 3) A random sample of 140 documents from the EHR at University College London Hospitals NHS Foundation Trust.
The KCH dataset (our largest one by a factor of 10) is the primary dataset where the base RoBERTa-Large model was first trained. Afterwards, the KCH model was transferred to GSTT and UCLH for further testing and fine-tuning. This was done to test can an original de-id model, which was trained on a large number of documents, be transferred and fine-tuned on a much smaller dataset without performance degradation.
Results
In Table 1, we show the performance of AnonCAT across the three hospitals. The models used are as follows: 1) KCH - Roberta-Large trained on 80% of KCH data and tested on 20%; 2) UCLH, we fine-tuned the KCH model on 80% of the UCLH data and tested on 20%; and 3) GSTT, we fine-tuned the KCH model on 80% of GSTT data and tested on 20%.

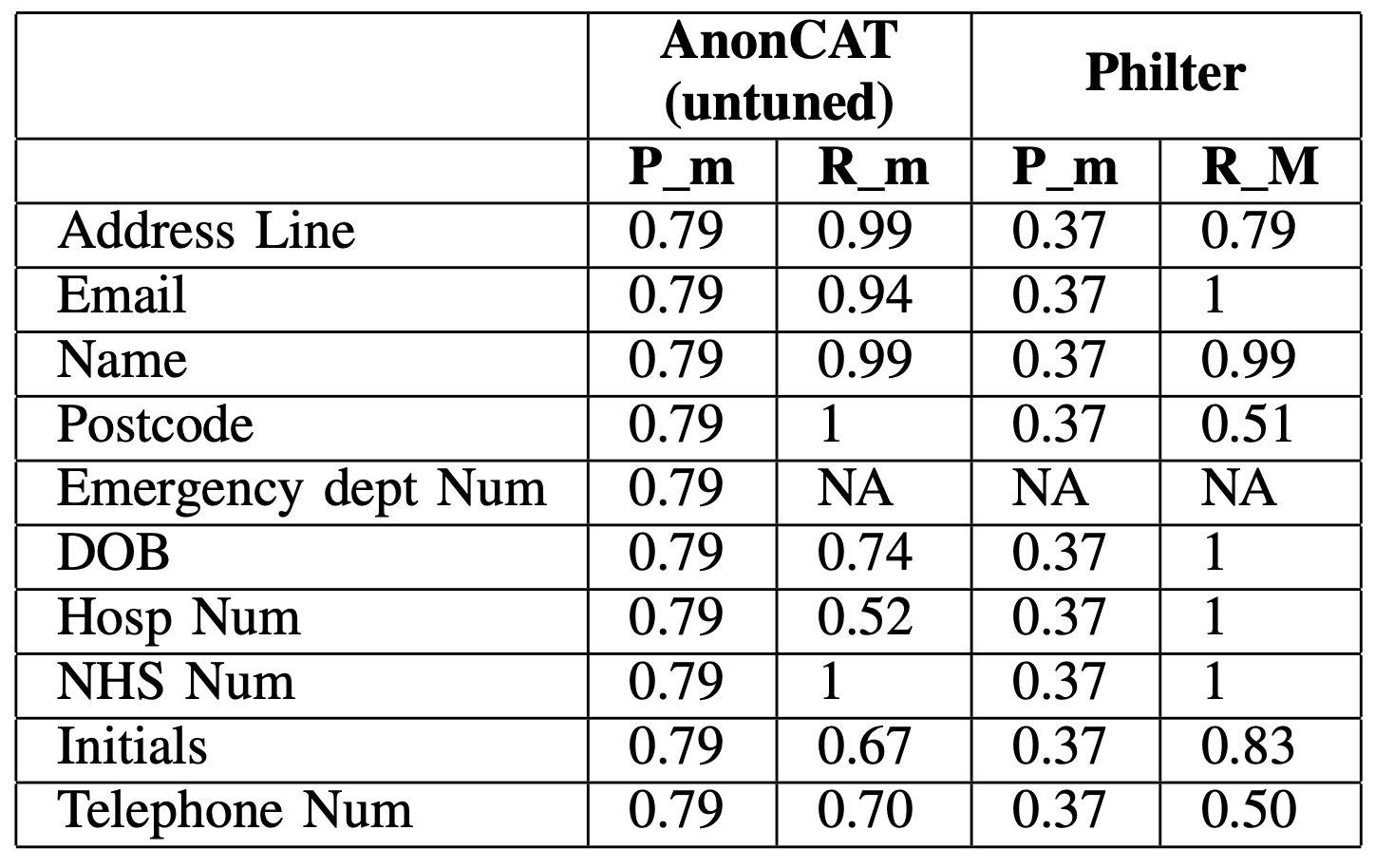
Next, in Table 2, we show the performance on the GSTT dataset for two different models. AnonCAT KCH, we test the KCH model on the full GSTT dataset without any fine-tuning, and Philter5 an off-the-shelf tool showing state-of-the-art performance on de-identification of clinical notes. The entities in Philter do not match exactly the entities we have in our concept database, so we only calculate the merged metrics for both Precision and Recall6.
Takeaways
With appropriate fine-tuning and maintenance, deep learning techniques offer an adaptable solution for improving the accuracy and efficiency of the redaction of EHR data. AnonCAT lays out a route for a foundational redaction NLP model that can be rapidly localised to a healthcare environment thereby reducing the rate of under-redaction (due to the uniqueness of patient data in new hospitals).
Table 2 shows that state-of-the-art off-the-shelf tools, as well as transformer-based models, require fine-tuning when applied to a new dataset if we want to achieve a Recall of 0.95+ (as shown in Table 1). We argue that a deep learning approach is easier to maintain and upgrade, as the only requirement for adapting it to a new dataset is annotating ~150 documents and running the fine-tuning.
If you would like to test these models yourself, I’ve made two Jupyter notebooks: 1) How to de-identify documents using an existing pretrained base model (link); 2) How to train a base model from the ground up (link).
I will focus mostly on AI researchers but use the term researchers in this blog post
https://www.techtarget.com/searchhealthit/definition/personal-health-information
https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-018-0623-9
https://www.medrxiv.org/content/10.1101/2022.09.15.22279981v2
https://www.nature.com/articles/s41746-020-0258-y
Recall_merged (equivalent for Precision_merged) ignores mistakes in-between concepts and only accounts for mistakes where something was supposed to be detected as PHI but was not. For example, if the token John was detected as Address, even though it is a name, the merged metrics will not consider this a mistake. But, if the token John was not detected at all, that would be a mistake. This was done because, for PHI data, it is a much bigger problem if we do not detect PHI, compared to mislabeling it as another concept.