


Hospital wide Natural Language Processing | Part 1 - MIMIC III
Decoding Gender and Age Patterns: An Examination of Physical and Mental Disease Prevalence Among MIMIC-III's Critical Care Patients

Electronic Health Records (EHRs) are a treasure trove of medical information. The data in EHRs is usually available in the form of free text and as such it is difficult to use and analyse. This means we first need to structure it. To do this we are going to use the Medical Concept Annotation Toolkit (MedCAT). MedCAT is used to extract and organize mentions of medical concepts (disease, symptoms, medications …) from free text. Once we have the information in a structured format, we can do an analysis and showcase the differences in disease frequency by age and sex.
This will be a two-part series based on a recent scientific paper I’ve published together with Daniel Bean. In part 1 we are going to use the data from MIMIC-III a freely-available database comprising de-identified health-related data associated with over forty thousand patients. These results from MIMIC-III are a bit more experimental and should be taken with a grain of salt, the main purpose was to showcase how MedCAT can be used. While in part 2 we will focus on the data from the King’s College Hospital in London with over 1M patients, these results were published in the paper and are much more strictly validated and examined.
Data Preparation
The MIMIC-III database is organized so that each document (EHR) has an ID and each ID is linked to a patient. For each patient, we also have information on age and gender. One patient can have 0 or more documents (clinical notes). The dataset is already nicely structured and can be fed into MedCAT directly. MedCAT was used to extract all diseases from the free-text portion of the dataset and link them back to the patients, if you want to learn how to use MedCAT please check the MedCAT Tutorials.
Results
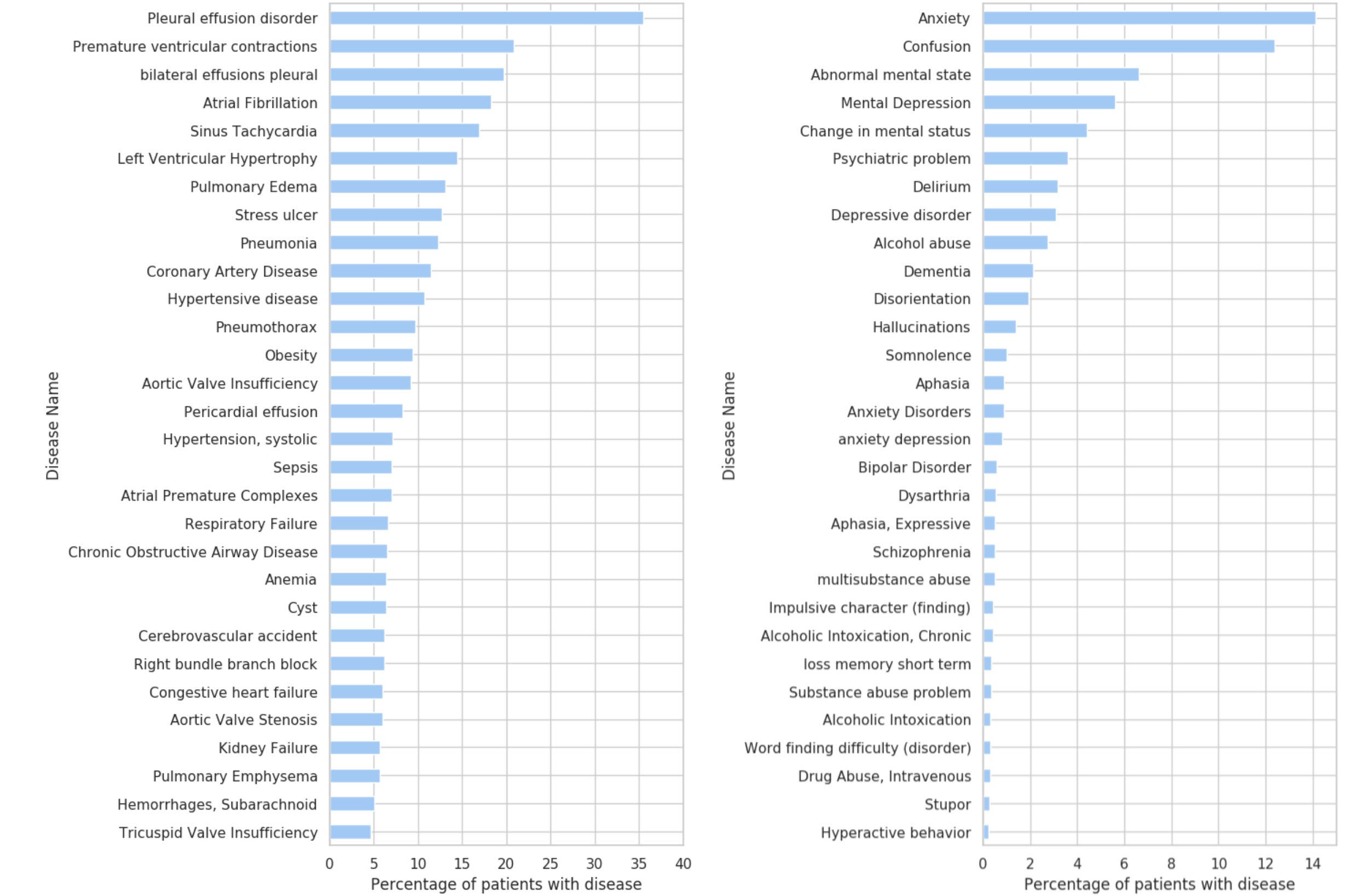
We start with a very simple representation of the most frequent mental and physical disorders in the whole dataset. For example, from Figure 1. we can see that around 35% of patients in the MIMIC-III dataset have Pleural effusion disorder, and 14% of patients have Anxiety. It is important to note that 1) MIMIC-III is a critical care dataset, so this does not reflect the distribution of diseases in the general public; and 2) These results are experimental, so mistakes in the annotation process (via MedCAT) are possible.
Because we have the information about sex from the structured portion of the MIMIC-III dataset we can now easily display the variation for each disease based on the sex of the patient (Figure 2).

The results shown in Figure 2 are supported by published work in the medical field. For example, Figure 2 shows that Depressive Disorder is more common in female than in male patients (supported by paper). Or that Substance Abuse (predominantly Alcohol) is much more common in male patients (supported by paper).
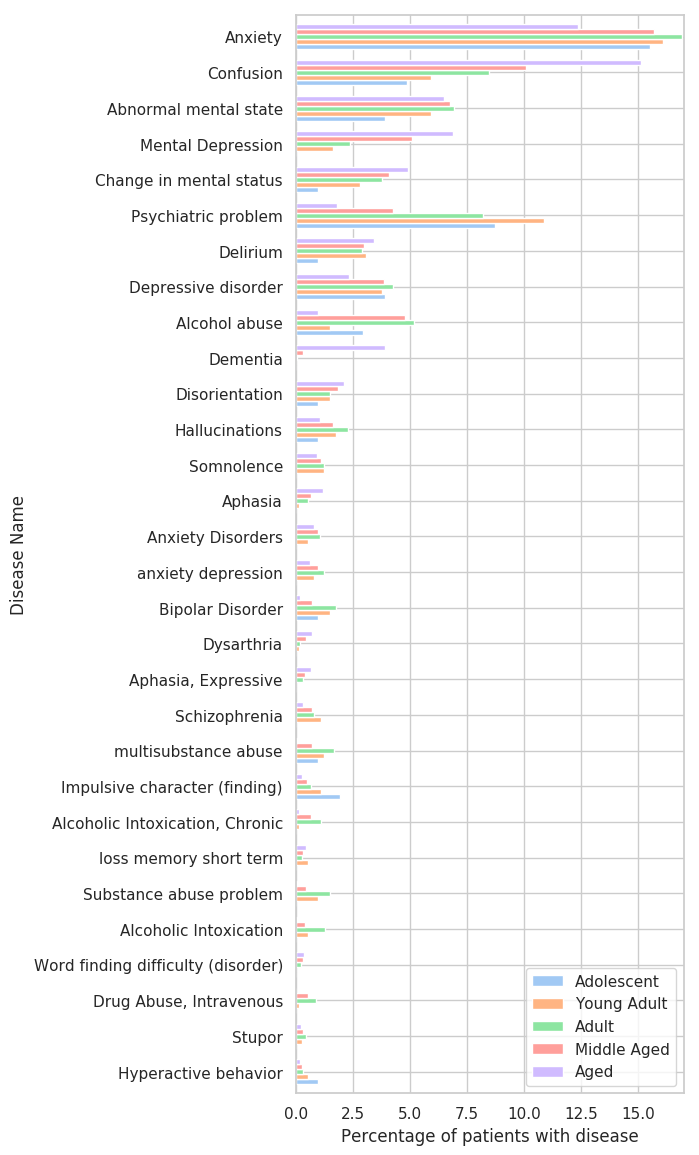
Lastly, because we have information about the patient's age from the MIMIC-III dataset, we will analyse the prevalence of diseases based on age. As it would be very messy to show age by year, we will group the patients as follows (taken from here):
Adolescent: 13 to 18 years
Young Adult: 19 to 24 years
Adult: 25 to 44 years
Middle Aged: 45 to 64 years
Aged: 64+ years

As it is expected, for most diseases, with age the percentage of people that have (or had) it increases.
Conclusion
The results obtained from the MIMIC-III database provide a fascinating glimpse into the potential of using the Medical Concept Annotation Toolkit (MedCAT) to streamline and enhance the analysis of Electronic Health Records (EHRs). By structuring the inherently nebulous, free-text data, MedCAT has demonstrated its potential to unlock a treasure trove of invaluable insights about disease prevalence based on age and sex.
It is important to underscore that this exploration represents an experimental journey into the promising field of medical Natural Language Processing (NLP). While the results yielded from the MIMIC-III database are experimental and should be treated as such, they reveal a new approach to comprehending the vast expanse of data contained in EHRs.
As we move towards the next part of this series, our focus will shift from the experimental to the validated. We will delve into data from King’s College Hospital in London, encompassing over one million patients. The intent is to uncover deeper, more nuanced perspectives about the healthcare landscape that will, in turn, inspire improved strategies in disease management, prediction, and prevention.
Stay tuned for the next part of this series, where we will continue our exciting exploration into the potential of MedCAT and NLP in healthcare, reaffirming their value and underlining their transformative potential in a domain that is increasingly becoming data-driven. Remember, this is not just about enhancing our understanding of healthcare data, but ultimately improving patient outcomes and the quality of care - a pursuit that we all can agree is of paramount importance.