
Clinical Coding with LLM Agents
A novel approach to NER+L using LLMs inspired by RAG. Easily switch between ICD10, ICD11, SNOMED, or any other ontology.

Years ago, I worked on a tool to do named entity recognition and linking (NER+L) for biomedical concepts from electronic health records (EHRs) and other medical texts. Back then, developing, testing, and refining took quite a bit of time. Recently, however, I have found a way to do this easily using large language models (as expected), with an approach inspired by retrieval-augmented generation (RAG).
If you're already familiar with the basics of named entity recognition and linking, feel free to skip directly to the "Clinical Coding with LLMs" section. The full code is a the bottom of the post.
This blog also has an audio voice over, please have a listen. I’ve made an agent to automatically process text, images and code and make a podcast friendly script, that is then read by a TTS model (all running locally, with no user interaction at all - took a bit to make). The models used were Deepseek R1 for planning, Qwen2.5VL for image and text processing and Kokoro for TTS. I' have ended up using a bit of Claude after everything, but will avoid in the future. The agent is given quite a bit of freedom to edit the text into an audio format, so strange things are possible. I did ask it to add a couple of jokes, but I do not think it went that well.
Introduction
In healthcare, data is everywhere, patient notes, clinical reports, prescriptions and most of it is written in free text. To effectively use this data, we first need to identify important biomedical concepts within it. This process is called Named Entity Recognition (NER).
Named Entity Recognition in healthcare involves extracting and recognizing specific biomedical entities from text. These entities can include diseases, symptoms, medications, and much more. But simply recognizing that something is a "disease" usually isn't enough. For instance, imagine looking at a patient's clinical note: just knowing that "something is a disease" won't tell us much. We need something more useful.
That's why, after identifying these entities, we typically link them to a standardized biomedical ontology a kind of official dictionary for biomedical concepts (e.g., ICD-10, SNOMED, and UMLS). This is called Linking (I know, very creative). Why is that important? Well, consider these different phrases: "T1DM," "type 1 diabetes," and "type I diabetes mellitus." They all mean the same thing. By linking them to the same standard concept in a biomedical ontology, we ensure consistency. This helps researchers, doctors, and even automated systems reliably understand what the data actually means.
Named Entity Recognition
There are plenty of ways to perform Named Entity Recognition, and methods have evolved quite a bit over time.
From an AI perspective, we can distinguish between traditional manual or rule-based NER approaches and more modern, automated approaches powered by machine learning. Unfortunately, the biomedical field often lags behind, with many approaches still being quite old-fashioned. You'd be surprised how many systems still rely heavily on rules, dictionaries, or simple string matching.
Here's a quick example of what NER might look like when identifying biomedical concepts with specific types (symptom, medication, disease, procedure, etc.):
Example clinical note:
The patient reports frequent headaches and was prescribed paracetamol.
Annotated:
The patient reports frequent <symptom>headaches</symptom> and was prescribed <medication>paracetamol</medication>.Typically, NER focuses purely on identifying these concepts. Linking them to biomedical ontologies the step that matches concepts with standardised identifiers is usually handled separately.
Linking to Biomedical Ontologies
Once we've identified biomedical concepts, we link them to standardized biomedical ontologies like ICD-10, SNOMED, or UMLS. Linking is often more challenging than expected because it requires accurately interpreting context. For instance, the abbreviation "DM" might refer to "direct message," "diabetes mellitus," or potentially many other meanings, depending on the surrounding text.
Generally, linking methods include:
Machine learning approaches, which use context to create numerical embeddings representing meaning, and then match these embeddings to ontology concepts.
Statistical approaches, which analyse surrounding words to find patterns indicating the correct meaning (e.g., if we have the term "DM" appearing near "high blood sugar" it is probably related to “diabetes mellitus” and not “direct message”).
In the sections below, I'll share how a recent afternoon experimenting with RAG-inspired approaches made me realize clinical coding can now be done much more easily using LLMs.
Clinical Coding with LLMs
Now, let's get to the main point, clinical coding with large language models. The idea here is straightforward and involves two primary steps we've discussed: detecting entities (NER) and linking them to an ontology. For simplicity, let's focus on diseases.
NER
First, detecting diseases is surprisingly simple with large language models. You can literally prompt the LLM with a phrase like "find all diseases mentioned in the following text," and it will reliably extract them (the prompt below is simplified, a slightly better one is needed if we really want state of the art performance).
... # See full code in the jupyter notebook at the bottom for details
system_prompt = '''
You are a medical text extraction assistant specialized in converting clinical notes into structured JSON data.
Your task is to extract all disease mentions from the input text.
Output:
- raw_string: the exact text extracted from the clinical note
- standardised_biomedical_name: the standardized biomedical name for the extracted disease (e.g., "T1DM" should become "Type 1 Diabetes Mellitus")
Input:
'''
class Entity(BaseModel):
raw_string: str = Field(default=None, nullable=True)
standardised_biomedical_name: str = Field(default=None, nullable=True)
class Entities(BaseModel):
entities: List[Entity]
response = client.models.generate_content(
model='gemini-2.0-flash',
config={
'response_mime_type': 'application/json',
'response_schema': Entities,
},
contents=system_prompt + "\n" + clinical_note,
)
...With this step, we've efficiently identified and standardized all diseases mentioned in the clinical note. This example is oversimplified but should sufficiently convey the core idea. LLMs handle the standardisation part especially well because they inherently understand context and meaning. Whether a hospital uses obscure abbreviations or local synonyms, the LLM can accurately expand abbreviations, decode synonyms, and normalize terminology, making the clinical coding process significantly simpler and more reliable. And if something is really strange, it can easily be added to the prompt/context.
Example output given a clinical note as below (this is a synthetic note):
Date: 03/15/2025
Patient: Johnson, Robert M.
DOB: 05/22/1958
MRN: 763421
Provider: Dr. Michaels
...
ASSESSMENT/PLAN:
COPD - Exacerbation likely. Increase Symbicort to 160/4.5 BID. Add prednisone 40mg daily x5 days. Consider PFTs at next visit.
HTN - Suboptimally controlled. Increase lisinopril from 20mg to 30mg daily. Continue HCTZ 25mg daily. F/U BP in 2 weeks.
T2DM - Stable. Last A1c 7.3%. Continue metformin 1000mg BID and empagliflozin 10mg daily.
A-fib - Stable per pt. Continue apixaban 5mg BID. EKG today shows rate-controlled AF. Will discuss w/ cards re: rhythm control options vs. rate control.
MDD - Worsening symptoms. Increase sertraline from 50mg to 75mg daily. Refer to psychiatry for evaluation. PHQ-9 score today: 14.
OA - Worsening knee pain. Recommend PT referral. Consider ortho referral for evaluation for possible injection. Increase acetaminophen to 1000mg TID.
GERD - Refractory to current tx. Increase omeprazole to 40mg BID. Reinforce dietary modifications. Consider GI referral if no improvement.
Migraine - Stable. Continue sumatriptan 50mg PRN.
Insomnia - Chronic, worsening. Refer to sleep medicine. Trial of trazodone 50mg QHS. Sleep hygiene education provided.
Obesity - BMI 35.2. Nutritional counseling provided. Consider weight management program.
F/U: 4 weeks
Sarah Michaels, MD
Internal Medicine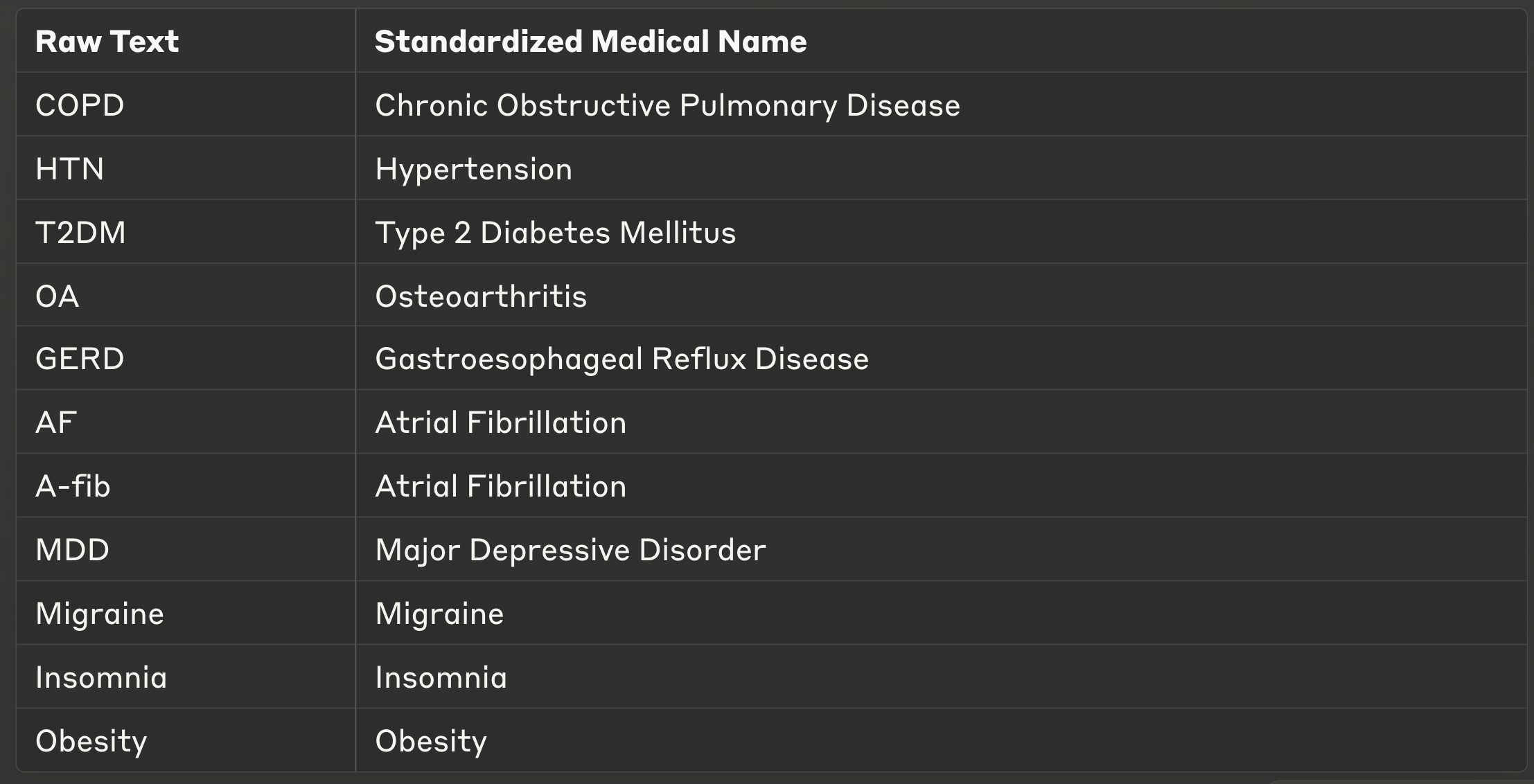
Linking
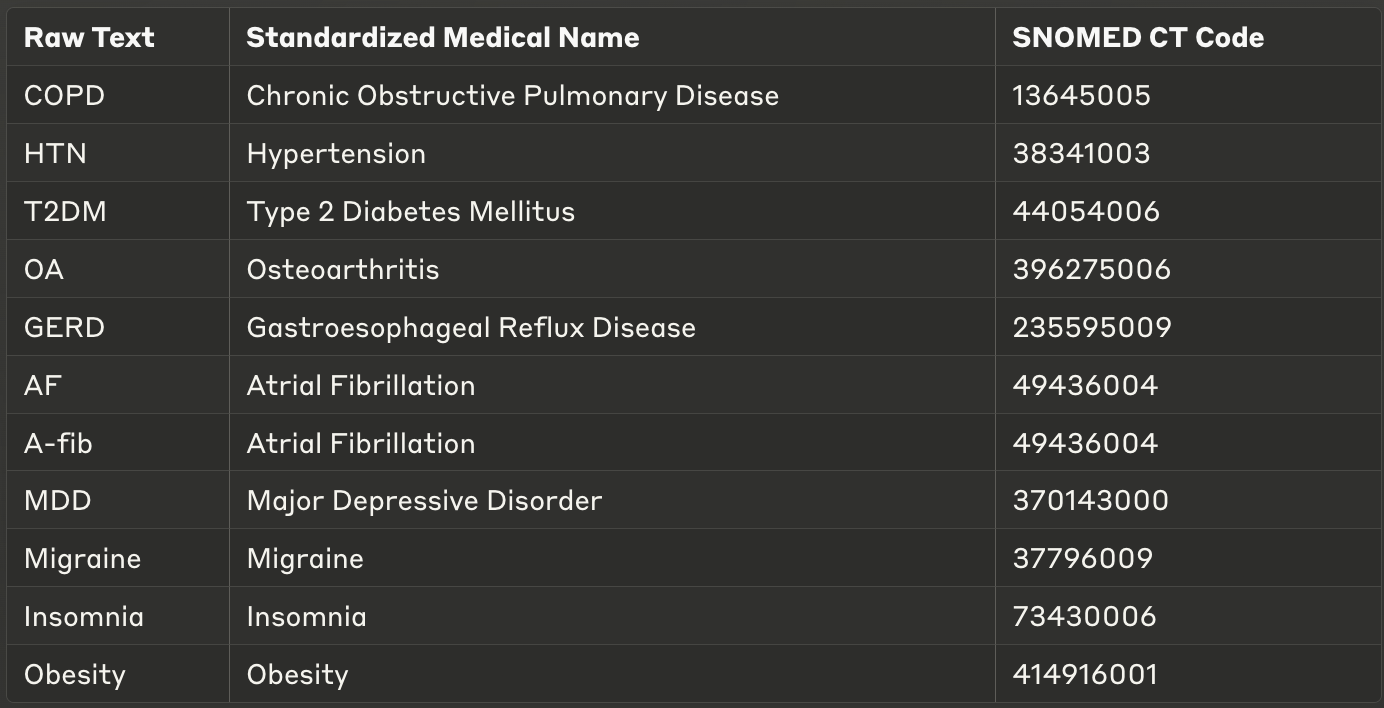
What is left now is linking. The idea is straightforward: we embed all standardized biomedical concepts (i.e. their primary names) from an ontology like SNOMED or ICD-10 using a compact embedding model, such as Qwen2 1.5B model. We then embed the standardized medical names of detected entities from the clinical notes (the output from the Gemini model above), compare them using cosine similarity, and link entities to the most similar concept from the ontology. We can easily implement a similarity threshold to ensure the reliability of the matches.
A bit annoying that ICD-10 is not open-source, so I had to make my own mini ontology. It is a small CDB (concept database) that has around 50 diseases with the appropriate SNOMED code.
Here's a code snippet demonstrating this approach:
... # See full code in the jupyter notebook at the bottom for details
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained('Alibaba-NLP/gte-Qwen2-1.5B-instruct', trust_remote_code=True)
model = AutoModel.from_pretrained('Alibaba-NLP/gte-Qwen2-1.5B-instruct', trust_remote_code=True)
# Extract ontology data, cdb = concept database
codes = [disease['snomed_code'] for disease in cdb['diseases']]
names = [disease['name'] for disease in cdb['diseases']]
# Embed ontology names
batch_dict = tokenizer(names, max_length=MAX_CONCEPT_NAME_LENGTH, padding=True, truncation=True, return_tensors='pt').to('cuda')
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# Normalize embeddings
concept_embeddings = F.normalize(embeddings, p=2, dim=1)
# Embed standardized entity names (entities detected in previous step)
# entity_embeddings = ... (embed your detected entity names similarly)
# Calculate similarity scores
scores = (entity_embeddings @ concept_embeddings.T) * 100
...And that is it, each entity detected in the free text can now be linked to the most similar concept from an ontology based on the similarity score. After linking concepts based on the similarity score, we get something like:
Limitations
While this approach offers significant efficiency gains, it's important to note that LLMs may occasionally hallucinate or misinterpret complex medical terminology. In my testing, I found error rates of approximately 3-5% for entity recognition and 2-3% for linking. I do think with better prompts, reasoning models or maybe changing the approach to be a bit more agentic, the score can be improved by quite a bit.
Conclusion
Leveraging large language models (LLMs) and embedding-based approaches significantly simplifies clinical coding, streamlining both the identification and standardization of biomedical concepts. This method offers notable advantages, including rapid updates when new ontology versions (e.g., updated SNOMED codes) are released, requiring only minutes for implementation. Additionally, models like Qwen 7B can be deployed on-premise, and with a bit of fine-tuning, their performance can match specialized cloud-based models. This on-premise capability addresses critical healthcare privacy concerns and regulatory requirements like HIPAA in the US or GDPR in Europe, making the approach viable even in highly regulated environments.
From a practical standpoint, this approach dramatically reduces the engineering effort required to build and maintain clinical NLP systems. What previously might have taken teams of engineers months to develop can now be implemented much faster. This efficiency translates to real cost savings and faster deployment cycles for healthcare organizations looking to extract value from their unstructured clinical data. While the example provided in this tutorial is intentionally simplified, there are numerous ways to enhance it improved prompting, incorporating reasoning models, fine-tuning, or even designing more sophisticated, agent-like workflows. Future developments might also include multimodal approaches that incorporate both textual and imaging data for a more comprehensive understanding of patient records. But exploring these advanced techniques is a topic for a future post.
Jupyter notebook link.
Thank you for reading,
Zeljko
Great post. I would like to highlight the relevant past challenge on SNOMED-CT linking here: https://www.drivendata.org/competitions/258/competition-snomed-ct/
Entity linking does not equal clinical coding. I've seen far too many LLM hallucinations in this area. Check out my blog post about this very specific topic: https://hadasbitran.substack.com/p/generative-ai-and-clinical-coding?r=kt7g9